Jamie Zawinski (program); Church of emacs (screenshot), CC Atribution, https://upload.wikimedia.org/wikipedia/commons/thumb/9/9b/The.Matrix.glmatrix.2.png/640px-The.Matrix.glmatrix.2.png
Questo scritto mira a delineare alcuni problemi riguardanti l’interazione, nel diritto dell’Unione Europea, tra politiche di apertura dei dati nel settore pubblico (Stato, pubblica amministrazione) e politiche sulla scienza aperta. Per un verso, essi riguardano la proprietà intellettuale: diritti di esclusiva riconducibili a brevetti per invenzione, diritti d’autore, segni distintivi, segreti commerciali. Per l’altro, concernono il controllo esclusivo dei dati non ascrivibile alla proprietà intellettuale come disegnata dalle normative internazionali e nazionali (proprietà intellettuale in senso stretto), bensì a un controllo esclusivo derivante da forme anomale di proprietà intellettuale (“pseudo-proprietà intellettuale”) e da un potere di fatto connesso alla tecnologia. Un controllo esclusivo che può sommarsi alla (o essere indipendente dalla) protezione legislativa della proprietà intellettuale.
La riflessione è innescata da una novità nella politica normativa dell’Unione Europea di apertura dei dati nel settore pubblico. La direttiva 2019/1024/UE del Parlamento europeo e del Consiglio del 20 giugno 2019 relativa all’apertura dei dati e al riutilizzo dell’informazione del settore pubblico (“Open Data directive” o “direttiva dati aperti”) determina un cambio di rotta sui dati della ricerca (art. 10, considerando 27 e 28), prima esclusi dalla materia e oggi invece oggetto di disciplina.
La tesi di questo scritto è la seguente. Oltre a creare infrastrutture pubbliche e a creare standard aperti per testi, dati e codici occorre comprimere e riordinare i diritti di proprietà intellettuale che insistono sui dati. La compressione e il riordino della proprietà intellettuale è uno degli strumenti per provare a diminuire il potere di mercato degli oligopoli dei dati. Da questa politica normativa dipende il futuro dell’autonomia e della libertà delle istituzioni di ricerca (prime fra tutte: le università) e in, ultima analisi, della democrazia.
Sommario
Introduzione
Scienza aperta o proprietà intellettuale?
Controllo dei dati e degli algoritmi
Controllo delle infrastrutture
Conclusioni
1. Introduzione
Questo scritto mira a delineare alcuni problemi riguardanti, nel diritto dell’Unione Europea, l’interazione tra politiche di apertura dei dati nel settore pubblico (Stato, pubblica amministrazione) e politiche sulla scienza aperta. Per un verso, essi riguardano la proprietà intellettuale: diritti di esclusiva riconducibili a brevetti per invenzione, diritti d’autore, segni distintivi, segreti commerciali. Per l’altro, concernono il controllo esclusivo dei dati non ascrivibile alla proprietà intellettuale come disegnata dalle normative internazionali e nazionali (proprietà intellettuale in senso stretto), bensì a un controllo esclusivo derivante da forme anomale di proprietà intellettuale (“pseudo-proprietà intellettuale”) e da un potere di fatto connesso alla tecnologia. Un controllo esclusivo che può sommarsi alla (o essere indipendente dalla) protezione legislativa della proprietà intellettuale.
L’art. 10 (dati della ricerca) della dir. 2019/1024/UE così recita:
“1. Gli Stati membri promuovono la disponibilità dei dati della ricerca adottando politiche nazionali e azioni pertinenti per rendere (‘politiche di accesso aperto’) secondo il principio dell’apertura per impostazione predefinita e compatibili con i principi FAIR. In tale contesto, occorre prendere in considerazione le preoccupazioni in materia di diritti di proprietà intellettuale, protezione dei dati personali e riservatezza, sicurezza e legittimi interessi commerciali, in conformità del principio «il più aperto possibile, chiuso il tanto necessario». Tali politiche di accesso aperto sono indirizzate alle organizzazioni che svolgono attività di ricerca e alle organizzazioni che finanziano la ricerca.
2. Fatto salvo l’articolo 1, paragrafo 2, lettera c), i dati della ricerca sono riutilizzabili a fini commerciali o non commerciali conformemente ai capi III e IV, nella misura in cui tali ricerche sono finanziate con fondi pubblici e ricercatori, organizzazioni che svolgono attività di ricerca e organizzazioni che finanziano la ricerca li hanno già resi pubblici attraverso una banca dati gestita a livello istituzionale o su base tematica. In tale contesto viene tenuto conto degli interessi commerciali legittimi, delle attività di trasferimento di conoscenze e dei diritti di proprietà intellettuale preesistenti”.
Dall’articolo emergono cinque principi sui dati della ricerca in riferimento all’obbligo rivolto agli Stati membri di adottare politiche nazionali e azioni pertinenti (“politiche di accesso aperto”):
1) apertura per impostazione predefinita;
2) compatibilità con le caratteristiche Findability, Accessibility, Interoperability, Reusability (FAIR), in italiano: reperibilità, accessibilità, interoperabilità e riutilizzabilità;
3) riutilizzabilità a fini commerciali e non commerciali nella misura in cui le ricerche sono finanziate con fondi pubblici e i dati sono stati resi pubblici attraverso una banca dati gestita a livello istituzionale o su base tematica;
4) i primi tre principi devono prendere in considerazione le “preoccupazioni” (“concerns” nella versione inglese) in materia di diritti di proprietà intellettuale, protezione dei dati personali e riservatezza, sicurezza e legittimi interessi commerciali e devono “tener conto” degli interessi commerciali legittimi, delle attività di trasferimento di conoscenze e dei diritti di proprietà intellettuale preesistenti.
5) il più aperto possibile, chiuso il tanto necessario (“as open as possible, as closed as necessary”).
Il principio n. 4) è, ai fini di questo scritto, quello più problematico. La sintesi tra le opposte esigenze di apertura e chiusura dovrebbe trovare espressione nel principio n. 5). Insomma, l’art. 10 getta un ponte tra politiche dei dati aperti nel settore pubblico e politiche in materia di Open Science: principi FAIR e principio “il più aperto possibile, chiuso il tanto necessario” sono, infatti, importati dalla politica europea in materia di scienza aperta.
La dir. 2019/1024/UE ha reso necessario un riordino normativo (rifusione) delle norme adottate nel 2003 (dir. 2003/98/CE, relativa al riutilizzo dell’informazione del settore pubblico) e nel 2013 (dir. 2013/37/UE, che modifica la dir. 2003/98/CE), non più adeguate al nuovo scenario tecnologico caratterizzato, tra l’altro, da Big Data, intelligenza artificiale e Internet delle cose [Pascuzzi 2020, 274]. Tale normativa incrocia ora la strategia europea in materia di dati, composta a sua volta di molteplici iniziative normative, e la nuova politica normativa in campo digitale.
Lo slogan che sintetizza sul sito web di riferimento la strategia europea in materia dei dati è formulato nel modo seguente:
“La strategia europea in materia di dati mira a fare dell’UE un leader in una società basata sui dati. La creazione di un mercato unico dei dati consentirà a questi ultimi di circolare liberamente all’interno dell’UE e in tutti i settori a vantaggio delle imprese, dei ricercatori e delle amministrazioni pubbliche.
Le singole persone, le imprese e le organizzazioni dovrebbero essere messe in grado di adottare decisioni migliori sulla base delle informazioni derivate da dati non personali”.
Tralascio considerazioni sugli obiettivi politici e sulla retorica di questo testo. Mi limito a osservare che il termine strategia è largamente abusato nei documenti politici e amministrativi, ma in questo caso il suo uso metaforico ha un nesso con l’etimologia militare. L’Unione Europea è nella tenaglia delle due superpotenze digitali (USA e Cina), e prova – almeno a parole – a difendere la propria autonomia facendo geopolitica dei dati.
“1. I dati della ricerca sono riutilizzabili a fini commerciali o non commerciali conformemente a quanto previsto dal presente decreto legislativo, nel rispetto della disciplina sulla protezione dei dati personali, ove applicabile, degli interessi commerciali, nonché della normativa in materia di diritti di proprietà intellettuale ai sensi della legge 22 aprile 1941, n. 633, e dei diritti di proprietà industriale ai sensi del decreto legislativo 10 febbraio 2005, n. 30.
2. La previsione del comma 1 si applica nelle ipotesi in cui i dati siano il risultato di attività di ricerca finanziata con fondi pubblici e quando gli stessi dati siano resi pubblici, anche attraverso l’archiviazione in una banca dati pubblica, da ricercatori, organizzazioni che svolgono attività di ricerca e organizzazioni che finanziano la ricerca, tramite una banca dati gestita a livello istituzionale o su base tematica.
3. I dati della ricerca di cui ai commi precedenti rispettano i requisiti di reperibilità, accessibilità, interoperabilità e riutilizzabilità”.
Il d.lgs 2006/36 fornisce all’art. 2 le definizioni di “dati della ricerca” e “dato pubblico”.
“Dati della ricerca: documenti informatici, diversi dalle pubblicazioni scientifiche, raccolti o prodotti nel corso della ricerca scientifica e utilizzati come elementi di prova nel processo di ricerca, o comunemente accettati nella comunità di ricerca come necessari per convalidare le conclusioni e i risultati della ricerca”.
“Dato pubblico: il dato conoscibile da chiunque”.
Il considerando 27 della dir. 2019/1024/UE offre alcuni esempi di dati della ricerca:
“[…] Sono dati della ricerca per esempio le statistiche, i risultati di esperimenti, le misurazioni, le osservazioni risultanti dall’indagine sul campo, i risultati di indagini, le immagini e le registrazioni di interviste, oltre a metadati, specifiche e altri oggetti digitali. I dati della ricerca sono diversi dagli articoli scientifici, in cui si riportano e si commentano le conclusioni della ricerca scientifica sottostante […]”.
L’art. 9-bis del d.lgs 2006/36 tace sulle “politiche nazionali di accesso aperto”, implicitamente rinviando ad altre sedi l’attuazione dell’obbligo della loro adozione (v. conclusioni di questo scritto a margine del Piano Nazionale per la Scienza Aperta preannunciato dal Programma Nazionale per la Ricerca 2021-2027), e mette in esponente il “principio di riutilizzabilità”.
A prima vista l’affermazione del “principio di riutilizzabilità” dei dati pubblici (non segreti, non riservati) della ricerca finanziata con fondi pubblici (derivanti dallo Stato) appare superflua. Secondo l’impostazione giuridica tradizionale i dati non possono essere oggetto né di proprietà (intesa in senso proprio, cioè come proprietà su beni tangibili, cose), né di proprietà intellettuale. Tuttavia, l’impostazione tradizionale appare contraddetta dall’evoluzione normativa e giurisprudenziale degli ultimi decenni che vede un’inarrestabile espansione della proprietà intellettuale sempre più vicina a comprendere i mattoni di base della conoscenza (dati e informazioni), la comparsa di forme anomale di esclusiva giuridica (“pseudo-proprietà intellettuale”) e l’emersione del controllo esclusivo di fatto basato sul potere tecnologico. Tra le forme anomale di esclusiva vanno annoverati, ad esempio, la titolarità dei dati da parte della PA, l’interazione tra contratto e misure tecnologiche di protezione dei dati e, in campo biomedico, l’esclusiva sui dati dei trials clinici. Il linguaggio della prassi spesso si riferisce a queste forme di controllo con l’espressione “proprietà dei dati” o “titolarità dei dati”.
Chi è promotore della scienza aperta dovrebbe accogliere con favore l’affermazione sul piano legislativo del principio di riutilizzabilità dei dati della ricerca. Tuttavia, per come formulato e disciplinato, a cominciare dalla clausola di salvezza “nel rispetto …” della proprietà intellettuale, il principio rischia di essere inutile. Ciò per diversi ordini di ragione.
a) La scienza aperta è inconciliabile con la continua espansione della proprietà intellettuale [David 2003]. L’Unione Europea e l’Italia non mostrano alcuna intenzione di voler invertire la tendenza espansiva della proprietà intellettuale. Anzi, i documenti programmatici – come il Piano di Azione della Commissione UE sulla proprietà intellettuale e la strategia sulla proprietà industriale del Ministero dello Sviluppo Economico – e le ultime normative – ad es. la direttiva 2019/790/UE -, provano esattamente il contrario: l’obiettivo è quello di rafforzare la proprietà intellettuale. Nemmeno la pandemia ha indotto un ripensamento [Caso 2020c]. Basterà qui ricordare che l’Unione Europea figura tra i più strenui oppositori della richiesta di sospensione dei TRIPS (gli accordi sulla proprietà intellettuale nell’ambito dell’Organizzazione Mondiale del Commercio), una misura temporanea che non mette in discussione il quadro di fondo [Caso 2021].
b) Il principio di riutilizzabilità non prevale sulla proprietà intellettuale, ma – come si è detto – la fa salva (considerando 54-56, art. 1.2 c) e d), art. 1.5) dir. 2019/1024/UE; art. 9-bis d.lgs. 2006/36).
c) Decenni di politiche di finanziamento e valutazione della ricerca hanno esaltato l’idea di premiare la c.d. “eccellenza”, instaurando un regime valutativo meritocratico, concentrando i fondi su pochi e scatenando una competizione tra ricercatori e tra istituzioni della ricerca per l’accaparramento delle poche risorse a disposizione. Le tradizionali norme informali della scienza aperta volte al comunismo della conoscenza sono state investite da pressioni che spingono a tenere i dati riservati. Di più, i ricercatori finanziati con fondi pubblici sono incentivati tramite regole valutative e prospettive di guadagno a reclamare diritti di proprietà intellettuale funzionali al trasferimento della tecnologia alle imprese, vero e proprio mantra delle politiche dell’innovazione.
d) L’apertura dei dati della ricerca deve tener conto di chi ha la disponibilità delle infrastrutture e del potere computazionale per poterli elaborare. Al momento molte di queste infrastrutture fisiche e logiche sono in mano a oligopoli commerciali che si trovano per la maggior parte fuori dell’Unione Europea. Il tema è ben presente alle istituzioni unionali, ma le misure finora messe in campo non sembrano sufficienti a risolvere il problema. L’apertura dei dati, senza infrastrutture al servizio di tutti, rischia di alimentare il potere degli oligopoli, il quale produce, tra l’altro, disuguaglianza.
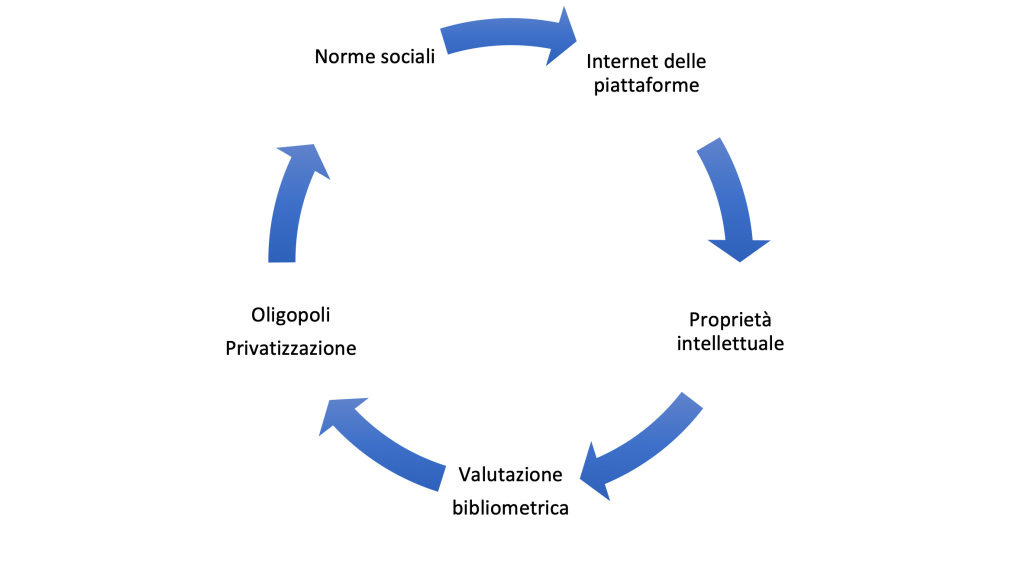
Si determina perciò un circolo vizioso. Le regole valutative incidono sulle norme sociali della scienza diminuendo la propensione a condividere i dati della ricerca. D’altra parte, in modo contradditorio, le politiche in materia Open Science spingono a condividere e ad aprire su Internet i dati mediante licenze che ne determinano – anche giuridicamente – la totale perdita di controllo [Pievatolo 2020b]. I dati aperti finiscono sotto il controllo delle piattaforme Internet che li difendono con la proprietà intellettuale e la pseudo-proprietà intellettuale nonché li elaborano con algoritmi a loro volta difesi da proprietà intellettuale (segreto commerciale). Parte di questo potere di controllo e computazione dei dati è usata per alimentare la valutazione bibliometrica, la quale genera il potere oligopolistico delle piattaforme che operano in campo scientifico. Questo ecosistema della proprietà intellettuale e della privatizzazione dei dati della ricerca mette a rischio le norme sociali della scienza volte al comunismo della conoscenza e in ultima analisi la democrazia [Pagano 2021].
Fig. 1: Il circolo vizioso di privatizzazione dei dati della ricerca
Il resto di questo scritto è organizzato nel modo seguente. Nel paragrafo 2 si mette in evidenza la contraddizione delle politiche europee: da un lato, promozione della scienza aperta, dall’altro, rafforzamento della proprietà intellettuale. Nel paragrafo 3 si descrivono le dinamiche di privatizzazione dei dati aperti basate sul controllo esclusivo di dati e algoritmi. Nel paragrafo 4 si passano in rassegna alcune proposte di cambiamento nella politica delle infrastrutture di ricerca col fine di restituire a settore pubblico, università, enti e istituti di ricerca il controllo dei dati. Nel paragrafo 5 si traggono alcune conclusioni anche in relazione al panorama italiano.
– la valutazione della ricerca (nuove metriche e un sistema di premi, incentivi e riconoscimenti ai ricercatori che praticano la scienza aperta);
– l’etica della ricerca (integrità e riproducibilità dei risultati);
– la formazione e le competenze in materia di scienza aperta;
– il coinvolgimento dei cittadini nella scienza (citizen science).
Tuttavia, sul piano dell’armonizzazione del diritto degli Stati membri l’intervento è stato limitato. I due interventi più direttamente pertinenti alla materia sono:
2) l’art. 10 della dir. 2019/1024/UE di cui qui si discute e che eleva a principio legislativo l’obbligo di adottare politiche nazionali di accesso aperto.
D’altra parte, sul fronte della proprietà intellettuale si marcia, come si è accennato nel primo paragrafo introduttivo, verso il continuo rafforzamento delle esclusive. Non è solo una questione di ampliamento delle esclusive esistenti, ma anche di proliferazione di nuovi diritti di esclusiva esclusiva [Resta 2011]: ad es., nuovi diritti connessi al diritto d’autore [Sganga 2021]. Questa legislazione alluvionale non presenta nemmeno definizioni condivise dei concetti fondamentali: dato e informazione. E deve coordinarsi con normative come quelle sugli Open Data e protezioni dei dati personali che definiscono in modo settoriale alcune nozioni (innanzitutto, la nozione di dato) [Guarda 2021, 11 ss.]. Insomma, il quadro legislativo si fa via via più intricato e confuso. Emerge plasticamente una contraddizione finora insoluta: da una parte, si promuove l’Open Science, dall’altra, si rafforza la proprietà intellettuale [Caso 2020a, 39].
Ad esempio, il diritto d’autore in linea di principio non conferisce un’esclusiva sui dati ma sulle opere dell’ingegno originali. Dell’opera dell’ingegno non sono vietati tutti gli usi. Si possono riprodurre le idee, i fatti, le informazioni e, appunto, i dati che compongono l’opera dell’ingegno. Non si può invece riprodurre la forma espressiva dell’opera. Il principio è conosciuto con la formula della distinzione tra idea (non protetta) ed espressione (protetta) o dicotomia idea/espressione. Ebbene, per quanto di difficile e controversa interpretazione (le definizioni giurisprudenziali di opera, idea, fatto e dato sono “liquide”), il principio ha costituito per molto tempo un baluardo della libertà di informazione ed espressione nonché della libertà di ricerca. Tuttavia, una serie di modifiche normative ne hanno ridotto la portata.
In particolare, la direttiva 1996/9/CE (direttiva banche dati) ha istituito un diritto sui generis (un diritto distinto dal diritto d’autore) in capo al costitutore di una banca dati.
La direttiva definisce la nozione di “banca dati”.
Per “Banca di dati” si intende una raccolta di opere, dati o altri elementi indipendenti sistematicamente o metodicamente disposti ed individualmente accessibili grazie a mezzi elettronici o in altro modo.
L’art. 7.1 e 7.4 della dir. 1996/9/CE così statuiscono:
“1. Gli Stati membri attribuiscono al costitutore di una banca di dati il diritto di vietare operazioni di estrazione e/o reimpiego della totalità o di una parte sostanziale del contenuto della stessa, valutata in termini qualitativi o quantitativi, qualora il conseguimento, la verifica e la presentazione di tale contenuto attestino un investimento rilevante sotto il profilo qualitativo o quantitativo. […]
4. Il diritto di cui al paragrafo 1 si applica a prescindere dalla tutelabilità della banca di dati a norma del diritto d’autore o di altri diritti. Esso si applica inoltre a prescindere dalla tutelabilità del contenuto della banca di dati in questione a norma del diritto d’autore o di altri diritti. La tutela delle banche di dati in base al diritto di cui al paragrafo 1 lascia impregiudicati i diritti esistenti sul loro contenuto”.
La direttiva si proponeva di incentivare la creazione di un florido mercato delle banche dati attraverso l’istituzione di un nuovo diritto di esclusiva (un diritto connesso al diritto d’autore). L’equazione alla base dell’intervento normativo era: più proprietà intellettuale = più innovazione. Insomma, la nuova esclusiva avrebbe dovuto aiutare le imprese europee nella competizione globale e in particolare nella competizione con gli USA.
L’equazione si è rivelata errata. Gli Stati Uniti pur non essendo – o forse, proprio per non essere – dotati di un diritto equivalente al diritto sui generis europeo hanno stravinto la competizione. La Commissione UE nel valutare l’impatto della direttiva ha, per ben due volte – nel 2005 e nel 2018 -, dovuto ammettere che non ci sono prove sull’impatto del diritto sui generis nella produzione di database. Nonostante ciò, la Commissione ha deciso di lasciare inalterata la direttiva.
Ma ora il vento sembra cambiare (almeno con riferimento alla direttiva banche dati). Nella strategia europea dei dati la parola d’ordine è diventata: condivisione [van Eechoud 2021].
Non a caso, l’art. 1.6 della dir. 2019/1024/UE (direttiva dati aperti) statuisce che:
“6. Il diritto del costitutore di una banca di dati di cui all’articolo 7, paragrafo 1, della direttiva 96/9/CE non è esercitato dagli enti pubblici al fine di impedire il riutilizzo di documenti o di limitare il riutilizzo oltre i limiti stabiliti dalla presente direttiva”.
La spinta verso la condivisione dei dati si vede anche meglio nella proposta del Data Governance Act (condivisione da parte del settore pubblico di dati non aperti e condivisione di dati tra imprese) e nelle premesse di quella che diventerà la proposta del Data Act (condivisione dei dati detenuti dalle imprese con il settore pubblico).
Tuttavia, nonostante tale spinta verso la condivisione dei dati, spalmata su un ventaglio di iniziative normative difficili da ricondurre a un sistema organico, il progressivo e inarrestabile rafforzamento della proprietà intellettuale continua a contrapporsi allo sviluppo della scienza aperta.
Un esempio è costituito dalla controversa direttiva 2019/790/UE (direttiva copyright), attuata in Italia con decreto legislativo 2021/177.
L’art. 3 della dir. 2019/790/UE è la disposizione normativa che riguarda più da vicino il tema dei dati della ricerca. La norma dispone un’eccezione ad alcuni diritti di esclusiva derivanti dal diritto d’autore e dal diritto sui generis sulle banche dati per consentire a organismi di ricerca e istituti di tutela del patrimonio culturale – come definiti dalla stessa direttiva – di effettuare l’estrazione, per scopi di ricerca scientifica, di testo e di dati da “opere” (protette da diritto d’autore) o altri “materiali” (protetti da diritti connessi) cui essi hanno legalmente accesso [Margoni, Kretschmer 2021]. Senza entrare nei dettagli, la norma, come quella che la attua in Italia, è contorta nonché presidiata da una serie di cautele, poste a presidio degli interessi dei titolari dei diritti di esclusiva, tanto ampia da ridurne fortemente la portata applicativa [Caso 2020b].
L’esempio merita di essere citato perché offre un’idea della politica legislativa dell’UE in materia di proprietà intellettuale. Tale politica si sostanzia nel rafforzamento del diritto di esclusiva che dovrebbe essere controbilanciato da specifiche eccezioni e limitazioni. Senonché il “sistema” delle eccezioni e limitazioni si è trasformato in un groviglio di norme disorganiche e in gran parte inutili. Ragion per cui non resta che sperare nei giudici, gli unici in grado di riequilibrare il rapporto tra esclusiva e libertà di uso mediante tecniche argomentative che eludono le restrizioni poste dalle eccezioni e limitazioni. Anche se occorre sottolineare che il ruolo della giurisprudenza nel campo del rafforzamento della proprietà rimane ambiguo: da una parte, contenimento delle esclusive, dall’altra, estensione delle esclusive legislative o addirittura creazione di nuove esclusive per via pretoria [Resta 2011].
3. Controllo dei dati e degli algoritmi
La filosofa della scienza Sabina Leonelli [Leonelli 2018, 29, 30-31] mette in evidenza due fenomeni:
a) il datocentrismo;
b) la combinazione di Big e Open Data.
“Nell’approccio datocentrico, i dati sono visti come entità pubbliche che hanno valore scientifico indipendentemente dal loro ruolo di prova per una determinata ipotesi e che possono essere interpretati in modi diversi a seconda delle abilità e degli interessi dei ricercatori che li analizzano. […]
L’ascesa del datocentrismo e la combinazione di Big e Open Data ha enormi implicazioni per come la ricerca scientifica – e in particolare l’organizzazione e l’utilizzo dei dati – viene condotta, organizzata, governata e valutata. La capacità dei dati di servire come fonte di conoscenza scaturisce dalla loro mobilità: ossia, dalla loro capacità di viaggiare attraverso diverse situazioni di analisi e riuso e di essere relazionati con quanti più tipi di dati diversi possibile”.
Insomma, una volta messi in Rete, i dati si muovono, viaggiano e dispiegano la loro natura non rivale: un dato non è come una cosa tangibile che è rivale all’uso, è invece usabile contemporaneamente da più soggetti. Sabina Leonelli ha dedicato molti anni delle sue ricerche per seguire i viaggi dei dati, concludendo che questi viaggi espongono la scienza datocentrica a diversi rischi, tra i quali risaltano: la produzione di conoscenza errata e la creazione o l’aggravamento di discriminazioni e diseguaglianze [Leonelli 2018, 43 ss.].
Per questo c’è bisogno di un’epistemologia dei dati che mitighi tali rischi.
Alcuni dei rischi messi in luce da Leonelli riguardano la commercializzazione dei dati della ricerca. I dati della ricerca possono, infatti, avere un grande valore economico.
Il fatto che le imprese possano giovarsi dei dati della ricerca finanziata pubblicamente è un aspetto fisiologico in un sistema capitalistico che potenzialmente è in grado di generare innovazione [Gold 2016]. Ciò che non è fisiologico è l’uso scorretto dei dati da parte delle imprese. Ciò che è ancor più patologico è che Internet non è più un luogo dove trionfano la libertà e la concorrenza, ma è sempre più un ecosistema malato dove dominano alcuni grandi centri potere privato (Big Tech) e pubblico (Big Governement) e dove il confine tra privato e pubblico si fa alquanto sfumato.
I dati della ricerca una volta in circolazione vengono messi sotto il controllo del potere computazionale delle grandi piattaforme le quali li mischiano con altri dati, soprattutto con dati personali, per finalità che in gran parte attengono al “capitalismo della sorveglianza” [Zuboff 2019]. Li elaborano attraverso algoritmi di apprendimento automatico (c.d. intelligenza artificiale) che sono difesi da segreti commerciali.
In altri termini, i dati aperti della ricerca finiscono sotto il controllo esclusivo delle piattaforme che può rispondere a forme propriamente dette di proprietà intellettuale o a forme anomale di controllo esclusivo (“pseudo-proprietà intellettuale”). La pseudo-proprietà intellettuale, peraltro, tende a sfuggire al controllo giuridico – giudici, autorità amministrative – e ai meccanismi di bilanciamento tipici del diritto della proprietà intellettuale.
A tal proposito l’economista Massimo Florio [Florio 2021, 62] rileva quanto segue.
“Gli algoritmi con cui funzionano i motori di ricerca o le piattaforme social, per quanto segreti, non implicano conoscenze tecnologiche e scientifiche superiori a quanto sia alla portata dei dipartimenti universitari dove si fa ricerca avanzata sulla tecnologia dell’informazione, inclusa l’intelligenza artificiale e in generale le tecniche di trattamento dei Big Data. Al contrario, le sette sorelle dell’economia digitale attirano conoscenze e capitale umano mettendolo al servizio di un’agenda di accumulazione di capitale. Se questo avviene senza ostacoli è anche perché la legislazione che si è voluta applicare alla protezione del consumatore e alla regolazione del mercato in settori come ad esempio la telefonia mobile non si è voluta applicare a queste piattaforme. Non vi è nulla di intrinsecamente tecnologico in questo, è una scelta politica derivante da circostanze reversibili. Quindi se non esistono, o non sono dominanti, piattaforme digitali che si impegnino a lasciarci la proprietà dei nostri dati e a gestirli solo nell’interesse pubblico in base a un protocollo a tutti noto, senza finalità commerciali o di comunicazione politica, questo non è un caso. È una scelta politica […]” .
Che la situazione attuale sia frutto di decisioni politiche è un ormai un fatto assodato. Il giurista Cesare Salvi in proposito svolge le seguenti considerazioni.
“La creazione di ‘nuove proprietà’ da parte del diritto è stata studiata di recente da Katharina Pistor, e non riguarda solo gli strumenti finanziari […].
Per Pistor, il ‘Code of Capital’ è un processo di ‘codifica’ cioè di scrittura di un linguaggio (operata dagli studi legali, ma garantita dalla legislazione globale), attraverso il quale la qualifica di bene giuridico, cioè di oggetto di proprietà privata, viene attribuita a un numero crescente di entità, alcune delle quali ‘esistono soltanto nella legge’. In questo modo, tali entità diventano ‘capitale’.
Oggi la cosiddetta proprietà intellettuale […] è assimilata alla proprietà in senso proprio (lo dice esplicitamente l’art. 17 della Carta dei diritti dell’Unione Europea), attribuendo così allo sfruttamento economico della conoscenza le medesime garanzie accordate alla proprietà dei beni materiali. La figura è in costante espansione, comprende entità eterogenee configurate come oggetto di diritti proprietari.
I diritti d’autore e i brevetti nacquero, parallelamente all’invenzione della proprietà moderna, tra il Seicento e l’Ottocento, per tutelare – per un breve periodo – autori e inventori di beni socialmente utili. Negli ultimi decenni il neoproprietarismo ha stravolto la logica e le finalità del sistema. La brevettabilità è stata estesa dal prodotto alle fasi precedenti (la ricerca), un numero crescente di beni e di attività sono state rese meritevoli di protezione, la durata si è allungata, è fiorente un mercato dei brevetti […].
È anche protetto il potere di controllare, utilizzando tecniche sempre più raffinate, i flussi di informazione. Attraverso algoritmi tenuti segreti (‘il vero signore di questa epoca digitale’) in quanto considerati ‘proprietà intellettuale’, le grandi imprese della rete decidono quali ‘informazioni’ diffondere e come queste devono essere conosciute. […]
Siamo in presenza non di un effetto ‘naturale’ del progresso tecnologico, ma di decisioni politiche, tradotte in norme giuridiche.
L’idea di privatizzare internet […] aprendolo agli usi commerciali, è stata una decisione dell’amministrazione Clinton. […]
Chi immaginava la rete come un bene comune, ecosistema di una miriade di innovatori e interlocutori, si trova oggi di fronte a un luogo occupato da pochi proprietari monopolistici”. [Salvi 2021, 57-59].
Si assiste a un paradosso: la scienza aperta produce dati che dovrebbero servire a tutti e che invece vengono privatizzati.
“Da un lato l’esistenza di un vasto patrimonio di open science frutto della ricerca di migliaia di università ed enti pubblici di ricerca rappresenterebbe un grande potenziale per accrescere la giustizia sociale. Ma dall’altro quel patrimonio può produrre l’effetto contrario: le imprese private che si collocano a valle, grazie agli investimenti in conoscenza già realizzati a monte, con la loro attività di R&S, si appropriano privatamente della conoscenza” [Florio 2021, 63].
Non è un caso che alcuni critici dell’Open Science abbiano argomentato contro l’apertura sostenendo che si tratta di un meccanismo di produzione di dati finalizzato ad alimentare il capitalismo digitale [Hagner 2018].
Tra le voci critiche si può segnalare – per la sua rinomanza – lo storico e divulgatore Yuval Noah Harari [Harari 2017, 559, 582-583, 599] che parla della nuova religione dei dati: il datismo.
“Il datismo sostiene che l’universo consiste di flussi di dati e che il valore di ciascun fenomeno o entità è determinato dal suo contributo all’elaborazione dei dati […] Il datismo è nato dalla confluenza esplosiva di due maree scientifiche. Nei centocinquant’anni trascorsi dalla pubblicazione dell’Origine della specie di Charles Darwin, le scienze biologiche sono giunte a concepire gli organismi come algoritmi biochimici. Contemporaneamente, negli ottant’anni trascorsi da quando Alan Turing formulò l’idea della macchina che porta il suo nome, gli informatici hanno imparato a progettare algoritmi digitali interpretabili da elaboratori elettronici sempre più sofisticati. Il datismo mette insieme queste due concezioni, evidenziando che esattamente le stesse leggi matematiche si applicano sia agli algoritmi biochimici sia a quelli computerizzati digitali. Inoltre, questa nuova visione delle cose abbatte il muro tra animali e macchine, e prevede che gli algoritmi computerizzati alla fine decifreranno e supereranno le prestazioni degli algoritmi biochimici.
[…] Il datismo sostiene la libertà delle informazioni come il bene più importante. […]
La gente di rado si inventa valori nuovi. […]. Il datismo è il primo movimento, dal 1789, che ha creato un valore autenticamente innovativo: la libertà delle informazioni.
Non dobbiamo confondere la libertà delle informazioni con il vecchio ideale liberale della libertà di espressione. La libertà di espressione era data agli umani e proteggeva il loro diritto a pensare e dire quello che volevano – tra cui il diritto di tenere la bocca chiusa e i propri pensieri per sé stessi. La libertà delle informazioni, invece, non è data agli umani. È data alle informazioni. Inoltre, questo valore nuovo può ledere la tradizionale libertà di espressione degli umani, privilegiando il diritto delle informazioni a circolare liberamente sul diritto degli umani a possedere dati e restringerne il movimento […].
Un esame critico del dogma datista è forse non soltanto la più grande sfida scientifica del XXI secolo, ma anche il progetto politico ed economico più urgente. Gli studiosi di scienze biologiche dovrebbero chiedersi se perdiamo qualcosa quando concepiamo la vita come un processo di elaborazione dati e decisionale”.
Più di recente Kate Crawford [Crawford 2021, 127] ha denunciato ciò che si nasconde dietro la retorica dei dati e dell’apprendimento automatico.
“Espressioni come data mining e frasi come ‘i dati sono il nuovo petrolio’ rappresentano una modalità retorica che serve a spostare la nozione di dato da qualcosa di personale, intimo o soggetto alla proprietà e al controllo individuale a qualcosa di più inerte e non umano. I dati hanno iniziato a essere descritti come una risorsa da consumare, un flusso da controllare o un investimento da sfruttare. L’espressione ‘i dati come petrolio’ è diventata un luogo comune e per quanto faccia pensare ai dati come a un materiale grezzo da estrarre, raramente è servita ad evidenziare i costi delle industrie petrolifere e minerarie: lavoro a contratto, conflitti geopolitici, depauperamento delle risorse naturali e conseguenze che vanno ben oltre la durata della vita umana.
In definitiva, la parola ‘dati’ ha perso sostanza; nasconde sia le sue origini materiali che i suoi fini. E una volta concepiti nella loro astrattezza e immaterialità, i dati sfuggono più facilmente ai concetti e alle responsabilità dell’attenzione, del consenso o del rischio.”
Le preoccupazioni non finiscono qui. Non solo i dati aperti della ricerca finiscono nel controllo privato della conoscenza, ma vengono incrociati con i dati personali di terze persone e anche con i dati personali degli stessi scienziati.
Numerose analisi mettono in luce che il capitalismo della sorveglianza è pienamente in funzione anche nella scienza [Aspesi et al. 2019, 32; Deutsche Forschungsgemeinschaft 2021; R. Siems 2021; Pievatolo 2021b; Pooley 2021]. Singoli scienziati e comunità di ricercatori vengono costantemente sorvegliati per prevedere e, in ultima analisi, influenzarne il comportamento, più in generale per influenzare l’evoluzione della scienza. Per quanto concerne le università ciò avviene per quanto attiene alla ricerca, alla didattica e alla gestione amministrativa. Non sorprende perciò che sia nata una campagna di mobilitazione “Stop Tracking Science” che reclama la cessazione della sorveglianza dei ricercatori.
Nel documento di SPARC del 2019 [Aspesi et al. 2019] poi aggiornato negli anni successivi [Aspesi et al. 2020, Aspesi et al. 2021] si rileva come il mercato dell’editoria scientifica stia passando dai contenuti ai dati. In particolare, le imprese come Elsevier concentrano il loro business sull’analisi dei dati. Il modello commerciale estende il suo oggetto dalle riviste scientifiche e dai libri fino ad arrivare alla valutazione, agli strumenti gestionali e ai sistemi per l’apprendimento online con quel che ne deriva in termini di rischi per i dati personali [Ducato et al. 2020; C. Angiolini et al. 2020]. Il controllo dei dati relativi a studenti, docenti e ricercatori, risultati della ricerca e funzionamento delle istituzioni ha un valore economico enorme. Perciò l’Open Access alle pubblicazioni scientifiche praticato dalle imprese di analisi dei dati non è la via che conduce all’Open Science [Aspesi, Brand 2020].
4. Controllo delle infrastrutture
Molte delle analisi sui problemi legati alla privatizzazione dei dati della ricerca convergono nel delineare soluzioni che puntano a riprendere il controllo delle infrastrutture fondamentali della scienza o, per lo meno, ad affiancare infrastrutture indipendenti a quelle nelle mani degli oligopoli commerciali.
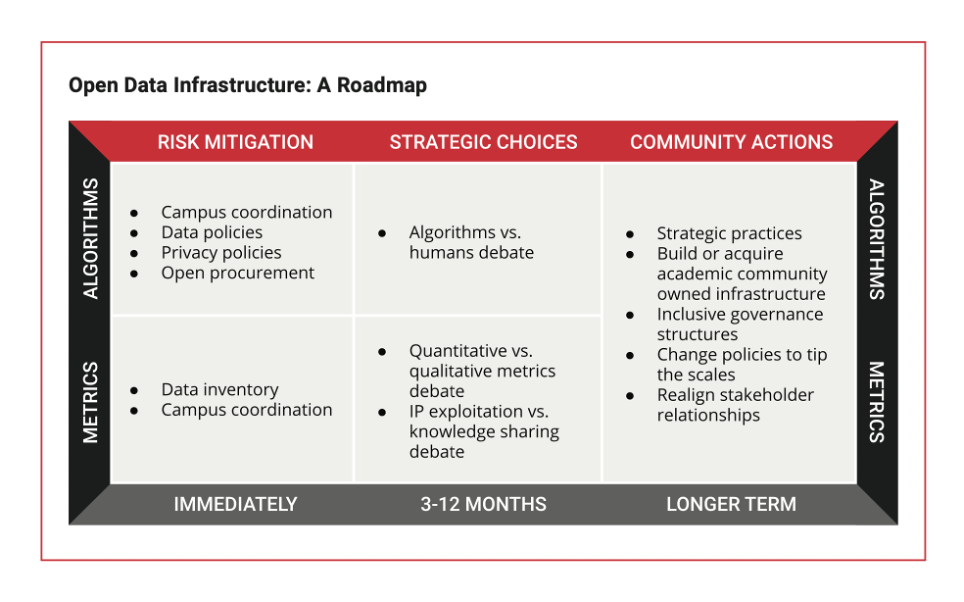
SPARC nel 2019 ha pubblicato una road map per le soluzioni organizzative necessarie per le università a riprendere il controllo di dati e infrastrutture [Aspesi, et al. 2019b]. La road map di SPARC è sintetizzata nella figura che segue.
Fig. 2: “Open Data Infrastructure: A Road Map” [Aspesi, et al. 2019b]
Il menu delle soluzioni si basa su due principi organizzativi. Il primo distingue metriche ed algoritmi. Il secondo distingue tre tipi di azioni (mitigazione dei rischi, scelte strategiche e azioni della comunità dei portatori di interesse).
Secondo SPARC le metriche – ciò che è oggetto di misura – dovrebbero essere nel controllo accademico, mentre gli algoritmi – come si misura – potrebbero anche non essere nel diretto controllo delle istituzioni accademiche, ma dovrebbero comunque essere trasparenti al fine di essere attentamente compresi e monitorati.
Esempi di azioni di mitigazione del rischio includono la predisposizione di meccanismo di coordinamento tra le varie strutture all’interno del campus, la revisione delle politiche sui dati, l’adozione di procedure trasparenti per l’acquisizione di servizi esterni.
Le questioni relative alle scelte strategiche comprendono quali metriche usare, in che misura fare ricorso all’intelligenza artificiale, l’alternativa tra proprietà intellettuale e condivisione della conoscenza.
Tra le azioni della comunità spicca la costruzione o l’acquisizione di una propria infrastruttura per la gestione dei dati.
Karen Maex rettrice dell’Università di Amsterdam – e anche Presidente della League of European Research Universities (LERU) – ha denunciato questo stato di cose nel discorso per l’inaugurazione del 389. Dies Natalis – 8 gennaio 2021 – dell’istituzione che governa [Maex 2021].
Maex denuncia il fatto che grandi compagnie private esercitano un ruolo sempre più importante nella vita delle università diminuendo il loro grado di autonomia e libertà.
L’erosione dell’indipendenza delle università è cominciata dalle biblioteche. Con il passaggio dalle biblioteche alle banche dati commerciali online le università hanno perso il controllo delle fonti di conoscenza. Dall’avere la proprietà dei supporti e il controllo della logica con cui ordinare le fonti (libri, riviste), le biblioteche universitarie si sono ridotte a intermediari per l’accesso e l’uso delle banche dati online pre-ordinate dagli editori commerciali. Quel che preoccupa di più è la perdita delle biblioteche come arene gratuite e aperte della ricerca. Il movimento dell’Open Access ha provato a ricostruire online queste arene, ma gli editori commerciali stanno prendendo il controllo anche dell’Open Access attraverso nuove formule contrattuali – i c.d. contratti trasformativi che dovrebbero condurre dagli abbonamenti per le banche dati ad accesso chiuso ad abbonamenti per pubblicare in accesso aperto [cfr. AISA 2020; Galimberti 2021] – i loro servizi valutativi.
L’erosione dell’indipendenza si è poi estesa ai dati della ricerca e agli altri dati prodotti dalle università (dati relativi alle abitudini di ricerca e lettura, dati relativi ai sistemi di didattica e apprendimento online, dati relativi alla selezione di studenti e docenti, dati relativi alla gestione amministrativa). I grandi editori commerciali come Elsevier, trasformatisi in imprese di analisi dei dati, sono penetratati a fondo nella vita delle università.
Nel riprendere il discorso di Karen Maex la filosofa politica Maria Chiara Pievatolo [Pievatolo 2021b] aggiunge la seguente nota a margine:
“La rettrice olandese è consapevole che chi domina i nostri dati organizza il modo in cui possiamo vederli o no, e, traendo dagli stessi strumenti di lavoro che ci vende altri dati sul nostro comportamento, è in condizione di creare un ambiente di scelta in grado di influenzare le nostre decisioni sulla ricerca, sulla sua valutazione e sulla selezione di ricercatori e studenti. Era una preoccupazione già fondata prima del passaggio forzato a una telematica integrale dovuto alla pandemia. Era infatti già possibile, per uno studioso, tener rinchiuso l’intero ciclo della sua ricerca entro un recinto e un controllo proprietario: ora, però, la saldatura fra i monopoli relativamente circoscritti dell’editoria scientifica e quelli globali di Microsoft, Google, Amazon, Facebook, Apple è divenuta pervasiva ed evidente”.
La questione nel riguardare il futuro dell’università, giocoforza riguarda il futuro della democrazia di cui le università, come luoghi di formazione della conoscenza e dello spirito critico, costituiscono un pilastro. Occorre perciò proteggere il carattere pubblico e autonomo della conoscenza prodotta nelle università.
Per difendere l’autonomia e la libertà delle università la rettrice Maex ritiene insufficiente la politica normativa europea attualmente in discussione, in particolare il Digital Services Act con le sue implicazioni in termini di maggiore trasparenza degli algoritmi alla base delle piattaforme Internet. Reclama invece l’introduzione di un Digital University Act che abbia quattro obiettivi.
1. Dati della ricerca. La conservazione e l’accesso ai dati della ricerca deve essere gestita da università e infrastrutture pubbliche.
2. Pubblicazioni scientifiche. Le pubblicazioni scientifiche devono essere in Open Access e non devono ingenerare alti costi per la pubblicazione o, peggio, dipendenza economica da un’impresa privata di analisi dei dati.
3. Strumenti per la didattica e per la ricerca. Le università devono avere il controllo degli strumenti digitali per la didattica e la ricerca. Tali strumenti dovrebbero far capo a piattaforme pubbliche o private, ma le università dovrebbero mantenere un controllo sui dati di uso e il potere di influenzare lo sviluppo degli stessi strumenti.
4. Dati delle piattaforme. Ricercatori e docenti devono avere accesso ai dati delle piattaforme per motivi di studio e insegnamento.
L’analisi delle debolezze della strategia europea dei dati e le proposte avanzate da Maex sono sostanzialmente riprese in un documento della LERU del dicembre 2021 [LERU 2021]. In tale documento, partendo dal rischio che la politica europea dei dati tratti le università alla stregua di imprese, le proposte vengono declinate e dettagliate su 16 principi rivolti a vari portatori di interesse: legislatori, digital providers, individui appartenenti alle università, università, industria.
L’iniziativa denominata Plan I – dove la “I” sta per Infrastructure – è stata avanzata da un gruppo di ricercatori tedeschi, tra questi si segnala il nome di Biorn Brembs, uno dei più autorevoli promotori a livello internazionale dell’Open Science [Brembs et al. 2021; Pievatolo 2021a]. Brembs e i suoi colleghi partono da un’analisi disincantata dell’attuale stato delle cose. Per trent’anni scienziati e ricercatori universitari hanno abbandonato il campo dell’innovazione delle infrastrutture di ricerca. Quel campo è stato occupato dai grandi editori commerciali come Elsevier, ora imprese di analisi dei dati, e dalle Big Tech come Microsoft.
Tutte le fasi del ciclo del lavoro dello scienziato che porta dalla ricerca e analisi dei dati, alla scrittura dei testi, fino alla pubblicazione, alla promozione (outreach) e alla valutazione dei risultati è occupato da poche grandi imprese commerciali (oligopoli).
Fig. 3: “Providers of digital tools for the scientific workflow (CC BY: Bianca Kramer, Jeroen Bosman, https://101innovations.wordpress.com/workflows). The preconditions for a functioning market exist, but a common standard is missing that provides for the substitutability of service providers or tools”. Tratta da Brembs et al. 2021
All’interno di queste infrastrutture commerciali attraverso tecnologie di sorveglianza e tracciamento le imprese estrapolano dati relativi al comportamento dei ricercatori che vengono sia venduti ad altre imprese sia sfruttati all’interno delle infrastrutture commerciali per rimodellare i propri modelli di business e offrire servizi alle istituzioni di ricerca.
La proposta Plan I si sostanzia in due punti.
1) Aprire gli standard di testi, dati e codici al fine di innescare la concorrenza dei servizi editoriali. In altri termini, l’apertura degli standard servirebbe a diminuire il potere di mercato dei grandi oligopoli. In particolare, servirebbe a distruggere il “vendor lock-in” (la dipendenza economica dal fornitore oligopolista).
2) Incentivare l’uso di standard aperti e riformare la valutazione della ricerca scientifica abolendo, secondo i principi della DORA declaration, criteri di valutazione che premiano la sede di pubblicazione invece del contenuto della pubblicazione.
L’obiettivo finale è quello di demolire il sistema oligopolistico di pubblicazione basato sulle riviste scientifiche (e sui servizi di analisi di dati) per costruire un mercato concorrenziale di servizi editoriali in cui testi, dati e codici sono liberamente accessibili e riproducibili. Secondo le stime di Brembs e dei suoi colleghi in un mercato concorrenziale di servizi editoriali le istituzioni di ricerca risparmierebbero il 90 % degli attuali costi di abbonamento alle banche dati oligopolistiche.
Una diversa proposta viene dall’economista Massimo Florio, sopra citato. L’alternativa all’oligopolio è rappresentata da una grande impresa pubblica europea di infrastruttura di ricerca [Florio 2021, 74 e 92].
“Si tratta di riscoprire l’idea dell’impresa pubblica e ibridarla con quella di infrastruttura di ricerca: un nuovo tipo di impresa come polo della creazione di conoscenza. Questo tipo di organizzazione potrebbe gestire come proprietà sociale il capitale intangibile derivante dalla ricerca pubblica in alcuni campi, creando un portafoglio di progetti i cui ritorni alimentino un fondo destinato sia a reinvestire nella stessa ricerca sia a programmi di promozione dell’uguaglianza nell’accesso alle nuove conoscenze. […]
Le proposte che seguono [Biomed Europa, Green Europa, Digital Europa] intendono quindi proporre soggetti unitari hub, eventualmente multicentrici, puntando su progetti su larga scala che integrino ricerca e servizio pubblico, intorno ai quali si possa aggregare una costellazione di altri soggetti pubblici e privati”.
Per quanto riguarda Digital Europa, l’infrastruttura che dovrebbe consentire di ripretendere il controllo dei dati, Florio dà conto delle iniziative in corso in Europa (Gaia-X e EOSC ecc.) e in Italia ICDI-Italian Computing and Data Infrastructure, ma le ritiene insufficienti.
“Nonostante questi segnali incoraggianti, difficilmente senza una vera infrastruttura sul modello delineato […] l’Europa recupererà il divario che si è creato con USA e Cina nella tecnologia dell’informazione e settori connessi. […]
Occorrerebbe immaginare un soggetto sovranazionale europeo che non abbia solo funzioni di coordinamento, ma abbia a tutti gli effetti autonomia manageriale, di bilancio, di capitale tangibile e intangibile, di personale dedicato con la missione di creare una piattaforma pubblica alternativa ai Tech Giants”.
Si è scelto qui di dar conto di alcune delle proposte di modifica delle politiche in materia di infrastrutture di ricerca. Si tratta di proposte che hanno elementi di differenziazione e convergenza. Segnalano che, rispetto solo a qualche hanno fa, c’è una maggiore e diffusa consapevolezza della malattia che affligge l’attuale ecosistema dei dati.
Tuttavia, tutte queste proposte lasciano immutato il quadro legislativo dei diritti di proprietà intellettuale e questo è un limite.
Oltre a creare infrastrutture pubbliche e a creare standard aperti occorre comprimere e riordinare i diritti di proprietà intellettuale che insistono sui dati. La compressione e il riordino della proprietà intellettuale è uno degli strumenti per provare a diminuire il potere di mercato degli oligopoli dei dati.
D’altra parte, le ricette in campo per contrastare gli oligopoli sono note e ampiamente discusse. Concernono politiche della concorrenza e della regolazione dei mercati, politiche fiscali, responsabilità, diritto dei contratti, protezione dei dati personali e, appunto, la proprietà intellettuale.
5. Conclusioni
L’Italia sconta un ritardo cronico in materia di Open Science. Il nostro Paese è da sempre all’inseguimento dei modelli più avanzati di scienza aperta.
Università, enti e istituti di ricerca pubblici mancano di strutture istituzionali di coordinamento all’interno (coordinamento tra dipartimenti) e all’esterno (coordinamento tra università, enti e istituti di ricerca). Poche istituzioni si sono dotate di politiche per la gestione dei dati della ricerca. Non ci sono numeri e statistiche circa lo stato di avanzamento della scienza aperta sul territorio nazionale. La formazione sulla materia è frammentata ed episodica. Il dibattito sulle infrastrutture per la ricerca e per la didattica è, come abbiamo visto, all’inizio, anche se non mancano infrastrutture già mature ed efficienti come quelle messe a disposizione dal consorzio GARR che necessiterebbero solo di essere ulteriormente sviluppate e promosse dai decisori pubblici [Nardelli 2020; Pievatolo 2020a; Barchiesi et al. 2021]. Il quadro giuridico è lacunoso, disarmonico e del tutto inefficace. La proposta Gallo (d.d.l. 1146) sull’accesso aperto all’informazione scientifica, che prevede tra l’altro l’istituzione di un diritto di ripubblicazione in Open Access in capo all’autore scientifico [AISA 2016; Caso 2020a; Caso, Dore 2021; Bellia, Moscon 2021], giace ferma al Senato da più di due anni. Persino il Piano Nazionale sulla Scienza Aperta preannunciato più di un anno fa nel Programma Nazionale della Ricerca 2021-2021 non riesce a vedere la luce (peraltro, l’adozione di politiche di accesso aperto è ora un obbligo per lo Stato italiano in attuazione dell’art. 10 dir. dir. 2019/1024/UE Open Data).
Soprattutto l’Italia è il Paese dove la proprietà intellettuale sui risultati della ricerca pubblica non è vista come frontalmente contraria alla logica dell’Open Science, ma come una leva fondamentale dell’innovazione e dove la valutazione bibliometrica di Stato, grazie anche all’onnipresente ANVUR, dilaga. La pandemia ha, inoltre, accelerato ed esteso la dipendenza delle università e delle istituzioni di ricerca dalle piattaforme commerciali [Fiormonte 2021; Monella 2021]. Al di là di poche eccezioni, la morsa del potere del potere delle piattaforme sulla didattica e sulla ricerca è sempre più stringente.
Quel che si riesce a fare per difendere l’autonomia e la libertà della ricerca scientifica lo si deve a poche istituzioni illuminate e a un manipolo di persone che ancora credono che l’art. 33 della Cost. non sia un simulacro, ma un principio fondante (ancora vigente).
Se c’è del buono nell’art. 10 della dir. 2019/1024/UE, cioè nel ponte gettato dal legislatore europeo tra politiche in materia di Open Data del settore pubblico e politiche in materia di Open Science, è che può essere un pretesto per riaprire un dibattito a livello di decisori pubblici – Governo, Parlamento – quanto mai urgente.
Anche dal controllo dei dati della ricerca dipende il futuro della democrazia. Un futuro che in questo periodo storico appare più cupo che mai.
M. Bellia, V. Moscon [2021], Academic Authors, Copyright and Dissemination of Knowledge: A Comparative Overview (October 28, 2021). Forthcoming in: C. Sappa, E. Bonadio(eds), Art and Literature in Copyright Law: Protecting the Rights of Creators and Managers of Artistic and Literary Works, Cheltenham: Edward Elgar Publishing, forthcoming, Max Planck Institute for Innovation & Competition Research Paper No. 21-27, Available at SSRN: https://ssrn.com/abstract=3970476
Join our upcoming workshop on legal aspects related to digitisation for Galleries and Museums (GM) on October 20-21, hosted by Museo Egizio (Egyptian Museum) in Turin, Italy.
Other contributors: Creative Commons + Creative Commons – Italian Chapter, Wikimedia Foundation + Wikimedia Italia, Europeana, Fondazione Torino Musei, inDICEs Project, ICOM Italia